Software Development Maintainer
Wstęp
Zapewne niejednokrotnie słyszałeś o module asyncio i korutynach, które pojawiły się od wersji Pythona 3.4. Muszę Ci szczerze powiedzieć, że początkowo byłem dość sceptycznie nastawiony do wspomnianej biblioteki. Jednak szybko zmieniłem zdanie, gdy standardowe podejście do wielowątkowości przy użyciu threading przestało spełniać moje oczekiwania. Była to sytuacja, w której realizowałem operacje I/O bound. Mimo że pracę wykonywałem na wielu wątkach, to bottleneck pojawił się, gdy konieczne było wysłanie 100 000 requestów i odebranie takiej samej ilości odpowiedzi. Wówczas dużym game changerem okazało się asyncio. I choć korutyny oraz keywords takie jak: async, await, event loop mogą na pierwszy rzut oka wydawać się dość złożone i nieoczywiste, to warto zapoznać się z ich użyciem i sposobami na implementację.
Asynchroniczność i asyncio
Asyncio umożliwia wykonywanie kodu asynchronicznie. Jest to sytuacja, w której wiele tasków wykonuje się "jednocześnie", bez konieczności czekania, aż zakończą się pozostałe. Stanowi to niezwykle istotne i znaczące rozwiązanie w dobie współczesnych programów, gdzie przykładowo potrzebujemy obsłużyć wiele tysięcy zapytań i przy tym nie zawieszać całej aplikacji.
Założę się, że do tej pory, multithreading implementowałeś tylko na wątkach. Asyncio jednak wprowadza nowy koncept, tzw. event loop. Jest to “główna pętla”, która umożliwia:
- rejestrowanie, wykonywanie i anulowanie wywołań
- delegowanie operacji do innych korutyn
Pracując z event loop, programiści jednak wykorzystują głównie wysokopoziomowe polecenia asyncio, jak asyncio.run() i rzadko odwołują się do omawianej pętli.
Wielowątkowość i asyncio
Jeżeli jesteś naszym kursantem, to zapewne już wiesz, że wielowątkowość, i biblioteka z nim związana - threading, jest tradycyjnym sposobem na uruchamianie tasków współbieżnie (współbieżność jest przeciwieństwem do równoległości i polega na tym, że joby uruchamiają się naprzemiennie jeden po drugim, sprawiając wrażenie, że działają równolegle). W artykule tym jednak omawiam asynchroniczność, nie równoległość. Są to zupełnie dwa różne pojęcia, a odnośnik do materiału opisującego różnice między nimi znajdziesz na końcu tego artykułu. Tak więc skupiać się będziemy na rozwiązaniu problemów I/O bound, a nie CPU bound.
Dlaczego zatem wspomniałem, że asyncio jest szybszym rozwiązaniem od multithreadingu, jeżeli oba podejścia są asynchroniczne? Odpowiedź jest prosta - asyncio oferuje wydajniejsze rozwiązanie pod kątem task schedulingu i zapewnia lepszą kontrolę nad flow programu. Przykładowo - możemy zatrzymać daną korutynę, wykorzystując słowo kluczowe await i w tym czasie przekazać czas procesora na wykonanie dowolnej innej operacji. W przypadku multithreadingu, to interpreter decyduje o schedulowaniu tasków. Programista w minimalnym stopniu ma wpływ na time slice-ing procesora.
Benchmarking
Przejdźmy do najciekawszej części tego szkolenia - wykorzystania asyncio w praktyce. Porównamy jego różnice w optymalizacji i działaniu względem synchronicznego i wielowątkowego podejścia do pisania programów.
Problem
Wyobraź sobie, że musisz w swoim programie wysłać 1000 zapytań na serwer. Każde z nich będzie pobierało komentarze z REST API - jsonplaceholder-a.
Synchroniczność
import time
def get_comments():
payloads = []
for i in range(1, 1000):
url = f"https://jsonplaceholder.typicode.com/comments/{i}"
resp = requests.get(url).json()
payloads.append(resp)
start = time.time()
get_comments()
end = time.time()
print(f“Elapsed time: {end - start}”)
Wszystko wykonało się poprawnie, jednak potrzebowałem dokładnie 163.793 sekundy na realizację funkcjonalności w nim zawartej. Wynika to z tego, że requesty wysyłane były jeden po drugim, w sposób synchroniczny (zapytanie nie może być wysłane zanim nie zostanie odebrana odpowiedź z poprzedniego). Ten fakt zmusza nas do zoptymalizowania rozwiązania. Musimy wprowadzić możliwość wykonywania kodu asynchronicznie - tak, aby requesty mogły być wysyłane naprzemiennie, bez konieczności czekania na odpowiedź poprzednio wysłanych.
Multithreading
Sprawdźmy teraz, jak nasz program zachowa się, gdy wykorzystamy multithreading i implementację opartą na wątkach. Wątki to części składowe danego procesu, które interpreter Pythona może przetwarzać asynchronicznie (co wynika z istnienia GIL-u). Zapytasz więc, czy w ten sposób nie wracamy do punktu wyjścia i nie otrzymamy takiego samego czasu wykonania, co w podejściu synchronicznym? No... nie do końca.
To dlatego, że serwis po otrzymaniu kilku requestów jest w stanie przetwarzać je w pełni równolegle i w rezultacie zwracać odpowiedzi z większą częstotliwością. Dlatego już teraz możemy przewidywać, że w ten sposób zoptymalizujemy nasz program wielokrotnie!
class ThreadRequests:
def __init__(self, urls: List[str], http_method: str, nb_threads: int = 2) -> None:
self.urlsQ: queue.Queue = queue.Queue()
self.infoQ: queue.Queue = queue.Queue()
self.nb_threads = nb_threads
self.http_method = http_method
self.workers = {"GET": self.worker_get, "POST": self.worker_post}
for url in urls:
self.urlsQ.put(url)
@property
def responses(self) -> List[Dict]:
return list(self.infoQ.queue)
def run(self) -> None:
for i in range(0, self.nb_threads):
threading.Thread(target=self.workers[self.http_method], daemon=True).start()
self.urlsQ.join()
def worker_get(self) -> None:
while not self.urlsQ.empty():
url = self.urlsQ.get()
resp = requests.get(url)
self.infoQ.put(resp.json())
self.urlsQ.task_done()
def worker_post(self) -> None:
while not self.urlsQ.empty():
url = self.urlsQ.get()
resp = requests.post(url)
self.infoQ.put(resp.json())
self.urlsQ.task_done()
comments = [f"https://jsonplaceholder.typicode.com/comments/{id}" for id in range(1, 1000)]
client = ThreadRequests(comments, "GET", nb_threads=5)
start = time.time()
client.run()
end = time.time()
print(f"Time elapsed: {end - start}")
Czas wykonania, jaki ujrzałem na ekranie to 31.833 sekundy! Zmiana stanowczo na lepsze, jednak drugą stroną medalu jest na pewno fakt, iż znacząco skomplikował nam się program i więcej nim zawiłości niż w podejściu synchronicznym.
W powyższym przykładzie, proces pobierania danych z serwisu jsonplaceholder przeprowadzany jest na 5 wątkach. Dodatkowo, aby skutecznie przetwarzać informacje i nie dopuścić do sytuacji, w której kilka wątków pobierze ten sam URL, wykorzystaliśmy kolejkę (Queue), która jest strukturą typu FIFO (First In - First Out) i świetnie nadaje się do przetwarzania asynchronicznego bez ryzyka wystąpienia data race. Rozwiązanie oparliśmy również o podejście OOP. Klasa ThreadRequests jest trzonem logiki biznesowej i odpowiada za uruchamianie wątków oraz przechowywanie kolejki “sygnałów”.
To teraz zapnij pasy! Mimo że czas wykonania operacji zredukowaliśmy o ponad 81% w podejściu wielowątkowym, to jesteśmy w stanie ograniczyć go jeszcze bardziej! A to właśnie dzięki wykorzystaniu asyncio.
Asyncio
W podejściu tym wykorzystamy event loop, który uruchamiany będzie, aby fetchować rezultaty wszystkich zapytań (uruchamianych asynchronicznie na oddzielnych korutynach; korutyny to najprościej funkcje oznaczone słowem async). Dodatkowo wykorzystamy zależności z biblioteki aiohttp, która pełni rolę HTTP klienta/serwera dla biblioteki asyncio. Biblioteka ta jest wręcz stworzona do pracy z asynchronicznym wysyłaniem requestów!
Sprawdźmy, jak teraz może wyglądać nasz program:
from typing import Callable, Coroutine, List
import aiohttp
import asyncio
import time
class HttpRequestSender:
async def get(self, session: aiohttp.ClientSession, url: str) -> Coroutine:
async with session.get(url) as response:
resp = await response.json()
return resp
class Fetcher:
@staticmethod
async def fetch_all(urls: List, inner: Callable):
"""Gather many HTTP call made async """
async with aiohttp.ClientSession() as session:
tasks = []
for url in urls:
tasks.append(
inner(
session,
url
)
)
responses = await asyncio.gather(*tasks, return_exceptions=True)
return responses
class Executor:
def __init__(self):
self.httpSender = HttpRequestSender()
def measure_time(func):
def inner(self, *args, **kwargs):
start = time.time()
func(self)
end = time.time()
print("=====================")
print("Run with asyncio!")
print(f"Elapsed time: {end - start}")
print("Not bad!")
print("=====================")
return inner
@measure_time
def run(self):
comments = [f"https://jsonplaceholder.typicode.com/comments/{id}" for id in range(1,1000)]
responses = asyncio.get_event_loop().run_until_complete(Fetcher.fetch_all(comments, self.httpSender.get))
executor = Executor()
executor.run()
Po uruchomieniu powyższego programu, otrzymałem następujący rezultat:
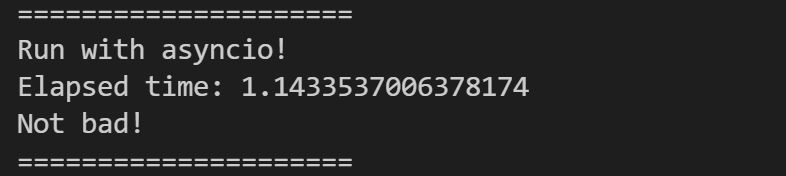
Bum! Zredukowaliśmy czas wykonania do 1.14 sekundy! Dla lepszego zobrazowania: program, który pierwotnie wykonywał się około 3 minut, teraz wykonuje się około sekundy! Dlaczego? Po pierwsze - pomogła nam w tym biblioteka aiohttp i jej asynchroniczny charakter oraz asyncio i uruchamiane korutyny zarządzane przez event loop. Dzięki temu czas procesora nie był zużywany na generowanie i zarządzanie wątkami. Mechanizm uproszczony do minimum.
Zakończenie
Artykuł ten ma stanowić zachętę do pogłębienia swojej wiedzy z zakresu asynchronicznego przetwarzania kodu. Jak już wiesz, asyncio jest nowoczesnym i efektywnym rozwiązaniem umożliwiającym współbieżne przetwarzanie kodu. Dlatego każdy profesjonalny programista powinien być zapoznany z konceptami przedstawionymi powyżej. Mentorujemy i wypuszczamy na rynek świadomych programistów, dlatego musimy stawiać poprzeczkę coraz wyżej i poruszać bardziej skomplikowane zagadnienia.
Jeżeli czujesz, że brakuje Ci podstaw z poruszonych wyżej zagadnień, zapytaj swojego mentora z Devs-Mentoring.p lub rozszerz wiedzę o następujące źródła zagadnień:











